
논문 : https://arxiv.org/abs/1904.01561
제목 : Analyzing Learned Molecular Representations for Property Prediction
발행일자 : 20 Nov 2019
저자: Kevin Yang, Kyle Swanson, Wengong Jin, Connor Coley, Philipp Eiden, Hua Gao, Angel Guzman-Perez, Timothy Hopper, Brian Kelley, Miriam Mathea, Andrew Palmer, Volker Settels, Tommi Jaakkola, Klavs Jensen, Regina Barzilay
1. 논문 개요 (Overall Summary)
이 연구는 분자 특성 예측 분야에서 주로 사용되는 두 가지 딥러닝 방법론의 성능을 광범위하게 비교 분석합니다. 첫 번째는 전문가가 설계한 분자 지문(Fingerprints)이나 기술자(Descriptors)를 입력으로 사용하는 신경망이고, 두 번째는 분자의 그래프 구조를 직접 학습하여 분자 표현을 스스로 구축하는 그래프 합성곱 신경망(Graph Convolutional Neural Network)입니다.
연구팀은 19개의 공개 데이터셋과 16개의 산업계(Amgen, Novartis, BASF) 비공개 데이터셋을 활용하여 기존 모델들과 자체 개발한 모델의 성능을 벤치마킹했습니다. 이를 통해 제안된
Directed Message Passing Neural Network (D-MPNN) 모델이 기존 방식들보다 더 뛰어나거나 동등한 성능을 보임을 입증했으며, 특히 산업 현장에서의 실제 적용 가능성을 높게 평가했습니다.
2. 서론 (Introduction)
문제 제기: 분자 특성 예측에 딥러닝이 활발히 도입되고 있지만, '학습된 분자 표현(Learned Representation)'과 '고정된 분자 지문(Fixed Fingerprints)' 중 어느 것이 더 우수한지에 대한 기존 연구들의 결론이 일치하지 않았습니다. 예를 들어, Wu 등의 연구에서는 그래프 기반 모델이 우수하다고 보고했지만, Mayr 등의 연구에서는 그 반대의 결과를 보였습니다.
연구 동기: 이러한 불일치는 데이터셋 구성 및 평가 방식의 차이에서 비롯된다고 보았습니다. 특히, 신약 개발과 같이 새로운 화학 공간(Chemical Space)에 대한 예측 일반화 능력을 측정하는 것이 중요한데, 기존 평가 방식은 이를 제대로 반영하지 못하는 한계가 있었습니다. 훈련 데이터와 테스트 데이터 간의 '분자 구조 골격(Scaffold)' 중복을 고려하지 않으면, 모델이 단순히 훈련 데이터의 구조를 암기하여 테스트 성능이 높게 나오는 과적합 문제가 발생할 수 있습니다.
연구 목표: 본 연구는 이러한 문제들을 해결하기 위해 (1) 포괄적인 평가 프레임워크를 설계하고, (2) 기존 모델들보다 우수한 새로운 알고리즘을 제안하는 것을 목표로 합니다.
3. 주요 연구 방법: D-MPNN 모델 (Key Methodology: D-MPNN Model)
연구팀은 기존의 Message Passing Neural Network (MPNN) 프레임워크를 개선하여 Directed-MPNN (D-MPNN) 모델을 제안했습니다.
3.1. 메시지 전달 신경망 (MPNN) 기본 개념
MPNN은 분자를 그래프로 간주하고, 두 단계로 작동하는 모델입니다.
- 메시지 전달 단계 (Message Passing Phase): 분자 내 원자(노드)들이 서로 정보를 주고받으며 분자 전체의 정보를 담은 신경망 표현을 만듭니다. 정해진 횟수(T steps)만큼 반복하여 각 원자의 숨겨진 상태(hidden state)를 업데이트합니다.
- 해독 단계 (Readout Phase): 최종적으로 학습된 원자들의 상태를 종합하여 분자 전체의 특성(예: 용해도, 독성)을 예측합니다.
3.2. 제안 모델: Directed-MPNN (D-MPNN)의 특징
D-MPNN은 기존 MPNN과 달리, **원자(atom)가 아닌 방향성을 가진 결합(directed bond)**을 중심으로 메시지를 전달합니다. (그림 1 참고 )
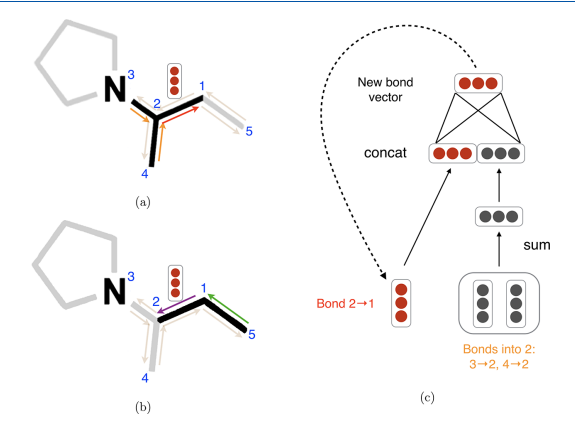
- 핵심 아이디어: 원자 기반 메시지 전달은 원자1 -> 원자2 -> 원자1 과 같이 불필요한 루프를 만들어 정보에 노이즈를 유발할 수 있습니다. D-MPNN은 결합 기반 메시지 전달을 통해 이러한 문제를 방지하고, 메시지가 더 효과적으로 분자 전체에 퍼지도록 설계되었습니다.
- 작동 방식: 각 방향성 있는 결합은 자신의 숨겨진 상태 벡터(hidden state vector)를 가집니다. 특정 결합의 상태를 업데이트할 때, 그 결합으로 들어오는 이웃 결합들의 정보만 합산하여 사용합니다. (그림 1c 참고 )
3.3. 모델 성능 향상을 위한 기법
D-MPNN의 기본 구조 외에 다음과 같은 기법들을 추가하여 성능을 극대화했습니다.
- 추가 분자 기술자 활용 (D-MPNN with Features): MPNN은 학습 데이터가 적거나 분자 전체의 광역적 특징이 중요할 때 성능이 저하될 수 있습니다. 이를 보완하기 위해, RDKit 라이브러리로 계산한 200개의 분자 수준 기술자(descriptors)를 학습된 분자 표현과 결합하여 최종 예측에 사용했습니다.

- 하이퍼파라미터 최적화 (Hyperparameter Optimization): 모델의 성능은 깊이(depth), 은닉층 크기(hidden size) 등 하이퍼파라미터에 크게 의존합니다. 베이지안 최적화(Bayesian Optimization)를 통해 각 데이터셋에 맞는 최적의 하이퍼파라미터를 자동으로 탐색했습니다.
- 앙상블 (Ensembling): 여러 개의 독립적인 모델을 학습시킨 후, 그 예측값들을 평균 내어 최종 예측을 수행하는 기법입니다. 이를 통해 단일 모델보다 더 안정적이고 정확한 예측을 할 수 있습니다.
4. 실험 및 결과 분석 (Experiments and Results Analysis)
4.1. 실험 데이터셋
- 공개 데이터셋: MoleculeNet, ChEMBL 등 19개의 공개 벤치마크 데이터셋을 사용했습니다. 이들은 양자역학, 물리화학, 생물리학, 생리학 등 다양한 분야와 크기를 포괄합니다.
- 산업계 비공개 데이터셋: Amgen, BASF, Novartis에서 제공한 16개의 실제 산업 데이터를 활용하여 모델의 실용성을 검증했습니다.
4.2. 평가 방법론
데이터 분할 방식: 모델의 일반화 성능을 정확히 측정하기 위해 'Scaffold Split' 방식을 주로 사용했습니다.
- Random Split: 데이터를 무작위로 훈련/검증/테스트셋으로 나눕니다.
- Scaffold Split: 분자의 핵심 구조(scaffold)를 기준으로, 훈련셋에 나타난 구조가 테스트셋에 나타나지 않도록 분할합니다. 이는 모델이 새로운 구조의 분자에 대해 얼마나 잘 예측하는지를 평가하는 더 현실적이고 어려운 방법입니다.
4.3. 주요 결과
- 기존 모델과의 성능 비교:
D-MPNN은 MoleculeNet의 최고 성능 모델들 및 Mayr 등의 모델과 비교했을 때, 다수의 공개 데이터셋에서 통계적으로 유의미하게 더 우수하거나 동등한 성능을 보였습니다.
특히, 하이퍼파라미터 최적화나 추가 기능 없이 '기본 설정'만으로도 Random Forest나 다른 FFN(Feed-forward Network) 기반 모델들보다 뛰어난 성능을 보여주었습니다.

- 산업계 데이터셋에서의 성능 검증:
Amgen, BASF, Novartis의 비공개 데이터셋에서도 D-MPNN은 다른 모든 베이스라인 모델들을 압도하는 성능을 보였습니다.
이는 공개 데이터셋에서의 우수한 성능이 실제 산업 현장의 데이터에도 그대로 적용될 수 있음을 시사하는 강력한 증거입니다.
- 데이터 분할 방식의 중요성:
실제 산업 데이터에서 흔히 사용되는 **'시간순 분할(Chronological Split)'**은 훈련셋과 테스트셋 간의 분자 구조(Scaffold) 유사성이 '무작위 분할(Random Split)'보다 훨씬 낮았습니다.
'Scaffold Split' 방식은 이러한 '시간순 분할'의 특성을 잘 모사하며, 'Random Split'보다 더 현실적인 성능 평가 지표임을 실험적으로 증명했습니다. 따라서 모델의 일반화 성능을 평가할 때는 Random Split보다 Scaffold Split을 사용해야 한다고 주장합니다.
- 모델 구성 요소별 영향 분석 (Ablation Study):
1. 메시지 전달 방식: 방향성 있는 결합(Directed Bond) 기반의 메시지 전달이 원자(Atom) 기반보다 평균적으로 더 나은 성능을 보였습니다.
2. 추가 기술자 (RDKit Features): 추가 기술자의 효과는 데이터셋에 따라 달랐습니다. 특히 데이터 크기가 작은 경우(예: PDBbind-C) 성능 향상에 큰 도움이 되었습니다.
3. 최적화 및 앙상블: 하이퍼파라미터 최적화와 앙상블 기법은 대부분의 데이터셋에서 모델 성능을 뚜렷하게 향상시켰습니다.

5. 결론 및 향후 연구 (Conclusion and Future Work)
결론: 연구팀은 광범위한 실험을 통해 '학습된 분자 표현'을 사용하는 D-MPNN 모델이 기존의 '고정된 분자 지문' 기반 모델들을 능가하며, 산업계에서 바로 활용될 수 있을 만큼 강력하고 안정적임을 입증했습니다. 또한, 모델 성능 평가 시 데이터 분할 방식(특히 Scaffold Split)의 중요성을 강조했습니다.
향후 연구: D-MPNN 모델이 여전히 약점을 보이는 부분들을 개선할 방향을 제시했습니다.
1. 3D 구조 정보 통합: 현재 모델은 2D 그래프 구조만 사용하므로, 분자의 3차원 좌표 정보를 활용하여 성능을 개선할 수 있습니다.
2. 데이터 부족 및 불균형 문제 해결: 데이터가 매우 적거나, 특정 클래스의 데이터가 극도로 적은(class imbalance) 경우에 대한 성능 개선이 필요합니다.
3. 사전 학습 (Pre-training): 대규모 화학 데이터셋으로 모델을 미리 학습시킨 후, 특정 소규모 데이터셋에 전이 학습(transfer learning)시켜 성능을 높이는 방안을 제안했습니다.
6. 종합 요약 (Executive Summary)
- 핵심 제안: 원자가 아닌 '방향성 있는 결합'으로 정보를 전달하는 D-MPNN 모델을 개발했습니다.
- 성능 입증: 35개(공개 19, 비공개 16)의 다양한 데이터셋에서 기존 최신 모델들보다 뛰어나거나 동등한 성능을 보였습니다.
- 실용성 검증: Amgen, BASF, Novartis 등 주요 기업의 실제 데이터에서도 우수한 성능을 보여 산업적 활용 가치를 증명했습니다.
- 방법론적 기여: 모델의 일반화 성능을 제대로 평가하기 위해서는 'Random Split'이 아닌 **'Scaffold Split'**을 사용해야 함을 실험적으로 강력하게 주장했습니다.
'머신러닝, 딥러닝' 카테고리의 다른 글
| 머신러닝 Task에서 효과적이었던 기법 (0) | 2025.07.15 |
|---|---|
| [논문 정리] Neural Message Passing for Quantum Chemistry(MPNN) (3) | 2025.07.07 |
| 명확한 평가 지표를 위한 핵심적인 기능 (0) | 2025.05.01 |
| [논문 매일 읽기 19일차] Llama 2: Open Foundation and Fine-Tuned Chat Models (0) | 2025.04.29 |
| [논문 매일 읽기 18일차] The Llama 3 Herd of Models (0) | 2025.04.29 |