
Microsoft AI School에서 지원 받은 계정을 이용해 로켓의 발사일 예측 모델을 구현해볼 것이다.
MS Azure의 Machine Learning Studio에서 Designer를 활용해 파이프라인을 구성하여 모델을 훈련시키고 평가할것이다.
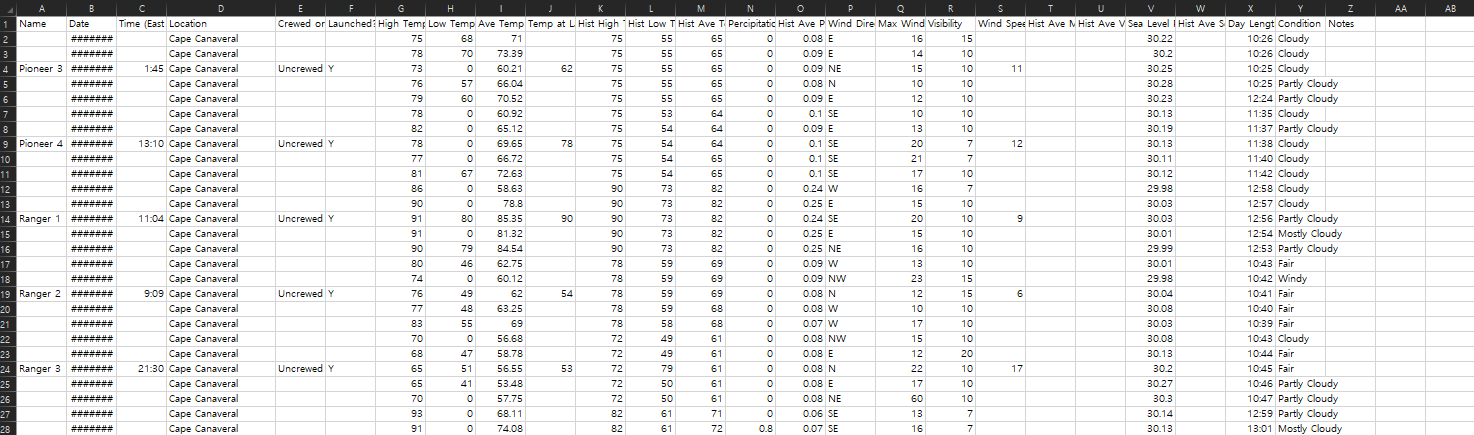
- 데이터세트 :
1958년부터 2020년 사이에 플로리다 케이프 커내버럴에서 나사가 발사한 유인/무인 로켓 발사 기록 총 60건
미국 해양 대기청에서의 플로리다 지역의 온도, 강수량, 풍향, 풍속 및 최대 풍속 등 날씨 관련 데이터
Weather Underground에서의 구름 및 번개 등 추가적인 날씨 데이터
- 알고리즘 :
발사 or 연기, 2가지 유형으로 예측하므로 머신러닝 중 지도 학습의 Classification을 사용
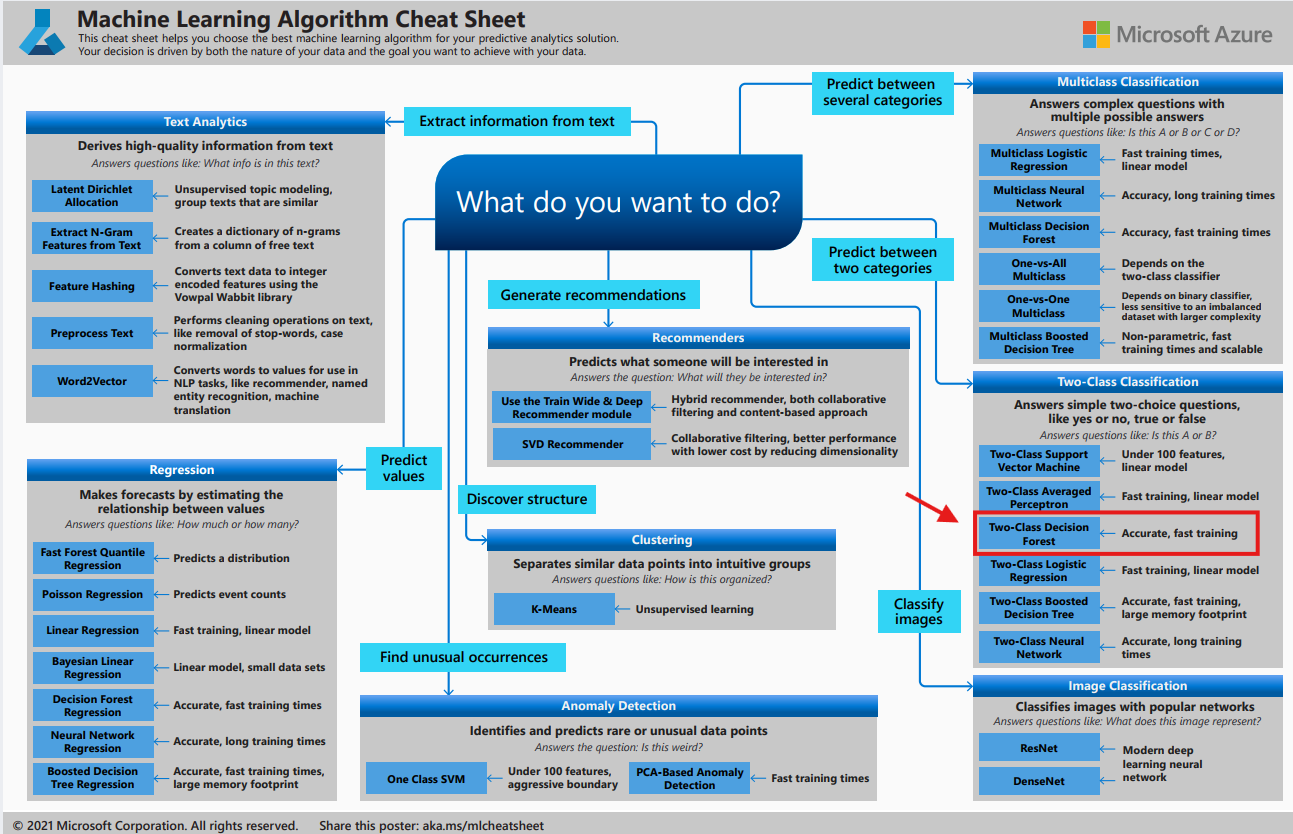
그 중에서 높은 정확도와 빠른 학습이 가능한 "Two-Class Decision Forest" 알고리즘 사용
Decision Tree(의사 결정나무) : 의사 결정 규칙을 Tree 구조로 표현하는 알고리즘, Classification을 예측하는데 주로 사용
=> 데이터를 가장 잘 분류할 수 있는 테스트,질문들을 이어가며 답을 찾아가는 방식
=> 각 테스트 조건은 동일한 범주( 순도가 높도록 )의 데이터가 모일 수 있도록 정함
=> 최대 깊이의 제한이 없으면 과대 적합(Overfitting)되기 쉬움 = 새로운 데이터에 대한 예측력이 떨어짐
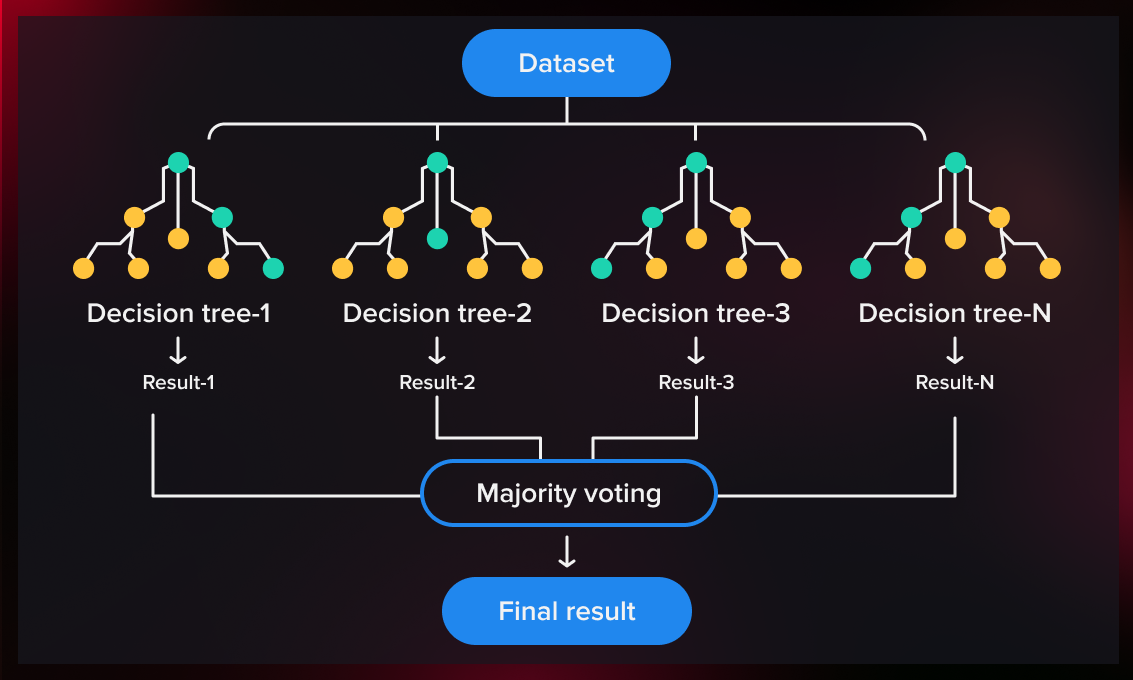
Random Forest(랜덤 포레스트) : 데이터셋에서 여러 번의 데이터 서브셋을 추출 후, "의사결정나무"를 각각 적용
=> Two-Class Decision Forest의 방법, 비교적 간단하지만 가장 강력한 머신러닝 알고리즘 중 하나
=> Bagging( 샘플링시 중복 허용 ), Pasting( 중복 허용X ) 둘 중 선택 가능
=> 하이퍼 파라미터 : 최대 깊이, 의사결정나무 개수, 중복 허용 여부, 리프 노드의 최소 샘플 수
( Ensemble learning( 앙상블 ) : 이건 여러 종류의 머신러닝 모델의 예측값을 종합해 다수결로 예측하는 방법 )
1. 리소스 그룹 만들기


리소스 그룹 -> "만들기" 클릭
- 구독 : 리소스가 함께 청구될 계정
- 리소스 그룹 : 그룹 이름( 식별 가능하게 생성 ) => 이름은 만들고 나서 수정 불가
- 영역 : 한국이면 "Korea Central"
2. Machine Learning Studio에서 컴퓨팅 생성
Azure에서 GPU가 있는 가상머신을 빌리기 위해 Machine Learning Studio에 들어가 컴퓨팅을 생성해야 한다.
우선 마켓플레이스에서 Machine Learning Studio를 생성
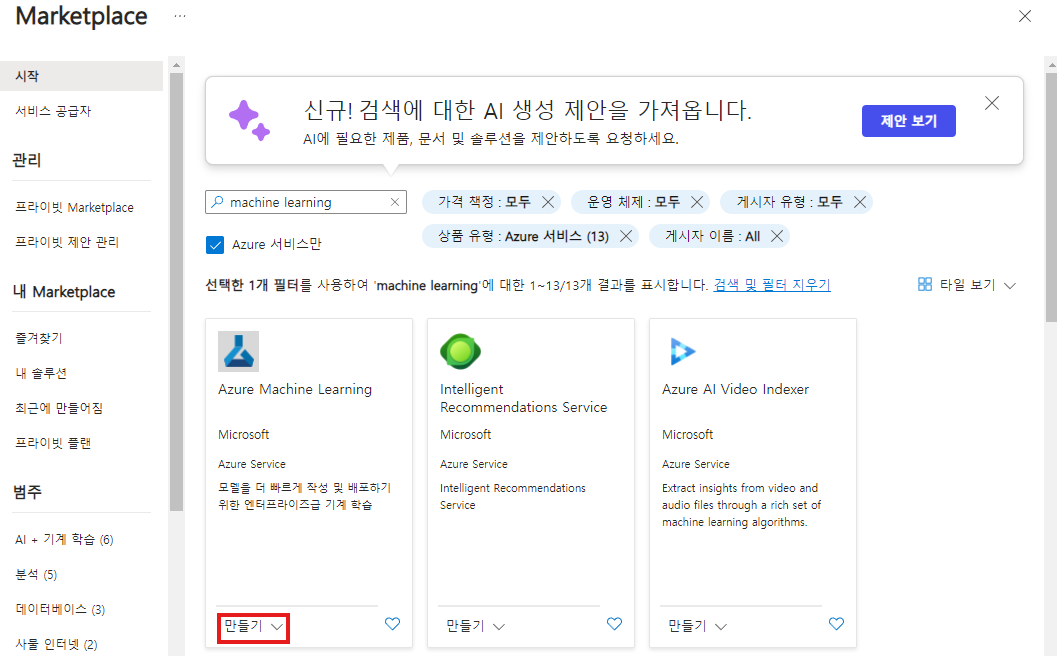
만들기 => "Azure 서비스만" 체크 => "machine learning" 검색후 "만들기" 클릭
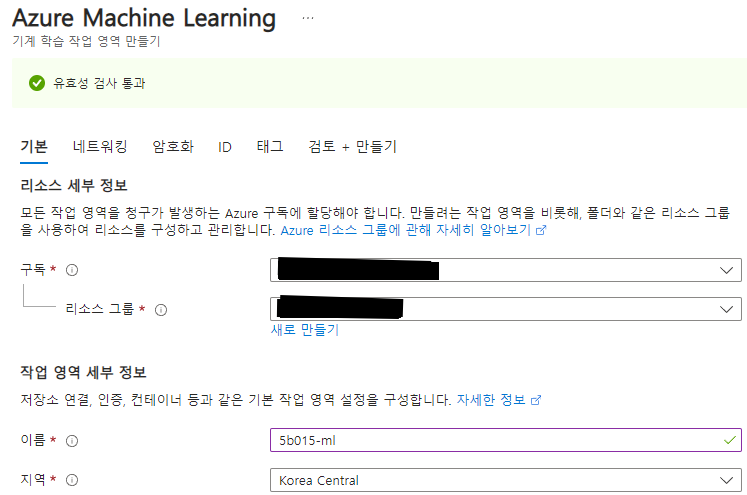
- 이름 : 5b015-ml
- 지역 : Korea Central
- 스토리지 계정, 키 자격 증명, 앱 인사이트 : 이름 설정하면 자동으로 지정
- 네트워킹 : 공개
만들기 => 배포 완료
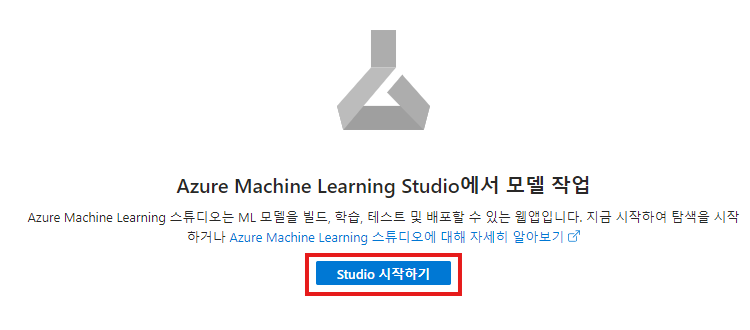
배포 완료되면 리소스로 이동후 "Studio 시작하기" 클릭
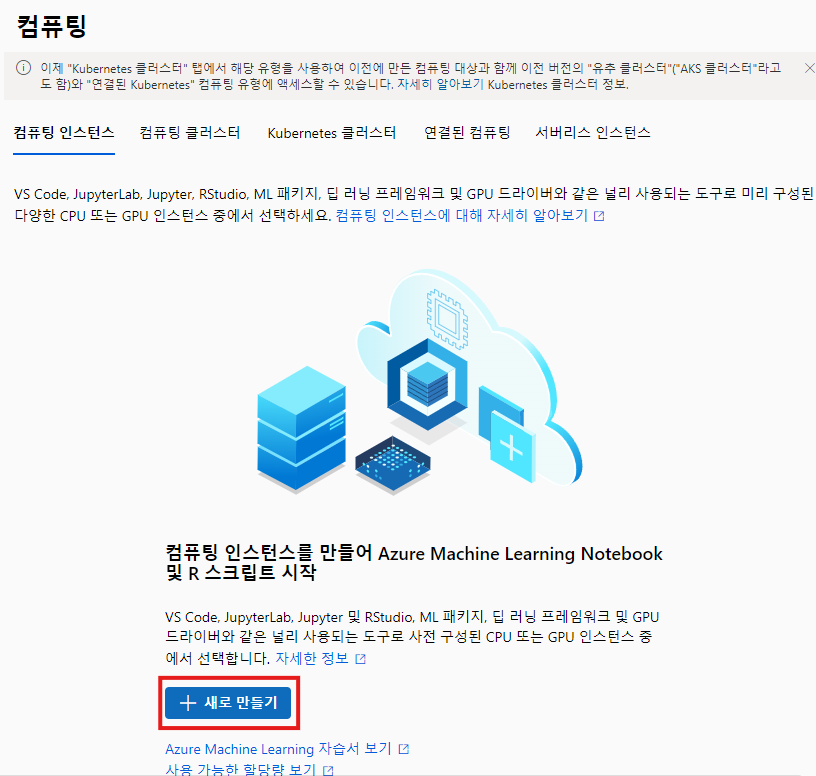
관리 - 컴퓨팅 으로 들어가서 컴퓨팅 생성

- 이름 : b015-ml-vm ( machine learning virtual machine이라는 뜻 )
- 가상 머신 유형 : CPU
- 가상 머신 선택 : Standard_D2_v3( 2코어짜리 )
- 일정 예약 : 사용하지 않으면 일정 시간 이후 자동 종료 설정 ( 60분 )

이 상태가 뜨면 컴퓨팅 실행 성공
3. 데이터세트 등록
Machine Learning Studio에서 Assets – Data 이동해서 "만들기" 클릭

- 이름 : rocket_launch_data
- 유형 : 표 형식(Tabular)
- 데이터 원본 : 로컬 파일에서
- 데이터 저장소 유형 : Azure Blob Storage - workspaceblobstore
( 데이터 저장소 : 로컬 파일을 업로드 한 후 저장하는 장소 )
( Azure Blob Storage : 대량의 비정형 데이터 특화 저장소 )
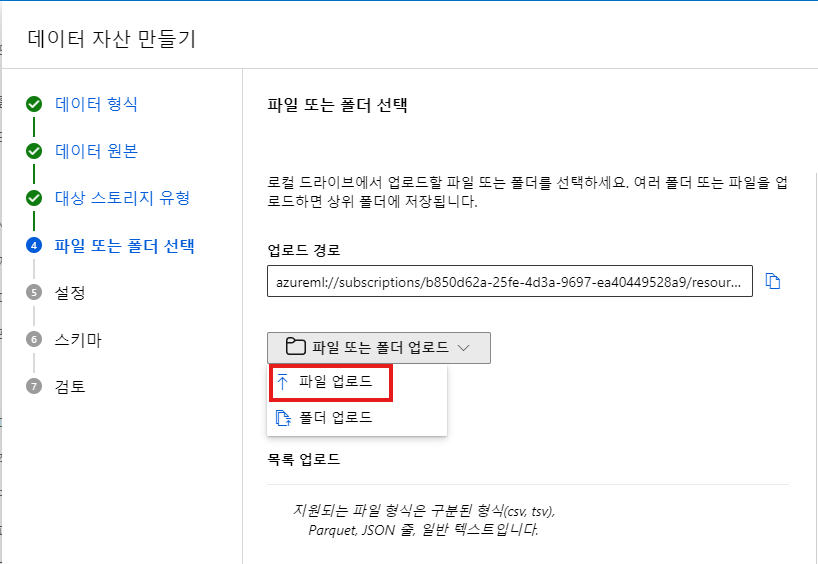
"파일 업로드" 클릭 후, 데이터 세트 파일 찾아서 파일 업로드( 여러 파일 형식 지원 )
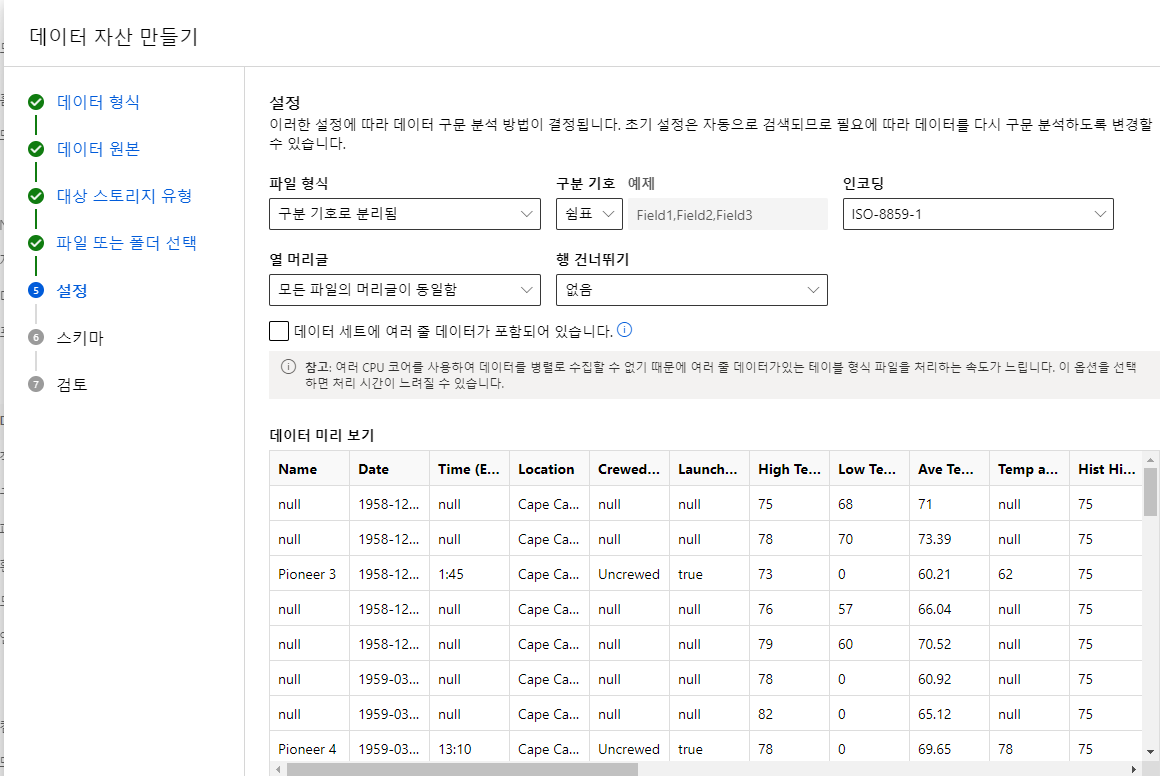
업로드 파일의 세팅을 점검하고 미리보기 확인
Schema 단계에서 컬럼 기준으로 데이터 타입 확인가능 => 온도 값은 실수(소수 구분(쉼표 ','))로 변경
검토에서 세부정보 확인후 '만들기' 눌러 데이터 세트 생성
Assets – Date에 생성된 데이터 세트 확인 가능
4. 머신러닝 디자이너 시작
Authoring(작성) – Designer(디자이너) 클릭
디자이너 : 머신러닝 파이프라인을 빌드하기 위한 “드래그 앤 드랍” 방식으로 구현하는 사용자 인터페이스
( Notebooks : 파이썬 코드로 직접 머신러닝 구현 )
( 자동화된 ML : 머신러닝 자동 구현 )
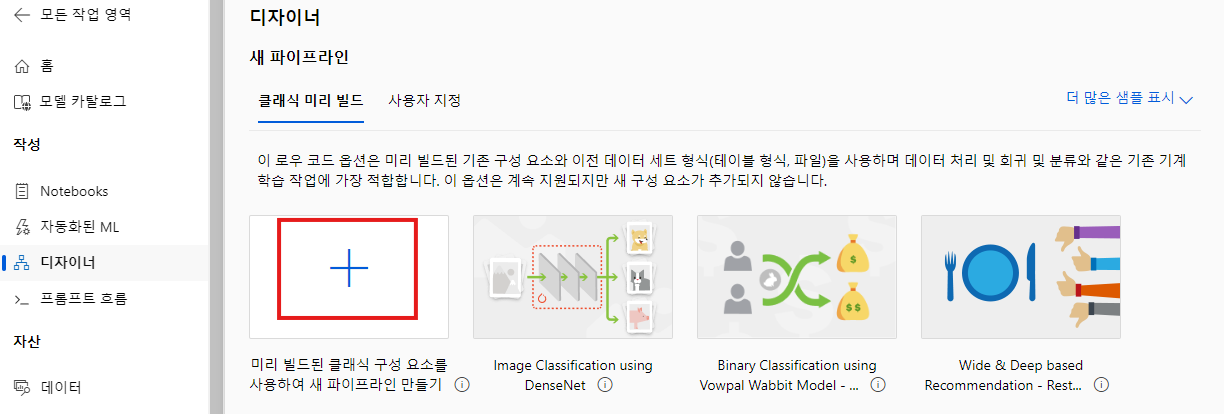
주어진 예제들에서 선택할수 있고, 옆에 +버튼 눌러서 새 파이프라인 생성

파이프라인 편집화면은 다음과 같은 3가지로 구성됌
머신러닝 작업에 필요한 데이터 및 컴포넌트 / 드래그-앤-드랍을 표시할 캔버스 / 세팅창
5. 데이터세트 전처리
'데이터'에서 우리가 만든 데이터세트 드래그앤 드랍으로 가져옴

< 불필요한 컬럼 제외 >
학습에 유의미한 데이터만 남기기 위해 필요 없는 컬럼들을 없애줄거임
Data Transformation에 "Select Columns in Dataset" 가져와서 연결해줌

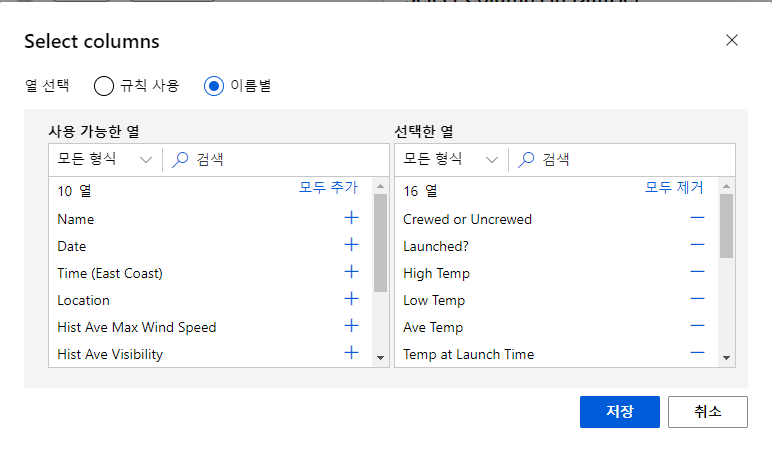
열편집 - 이름별에서 선택한 열에 남겨둘 컬럼만 남긴후 저장 (사용 가능한 열 : 제거할 컬럼)
< 누락값 처리 >
우리가 올린 데이터세트를 오른쪽 클릭후 '데이터 미리보기'를 클릭하면, '프로필'에서 누락값이 얼마나 있는지 확인 가능
누락값이 있으면 올바른 학습을 위해 어떻게 처리해줄지 정해줘야 한다.
현재 데이터세트에는 "Crewed or Uncrewed", "Launched?", "Wind Direction", "Condition" 이렇게 4개의 컬럼을 따로 처리해주고, "나머지 열"을 0으로 처리해줄 것이다.

컴포넌트에 “Clean Missing Data”검색후 드래그앤 드랍 – 연결

열 편집 - "Crewed or Uncrewed" 검색후 추가
Replacement value”에는 누락값을 어떤 값으로 대체할것인지 입력( “Uncrewed” )


Launched?는 'false' / Wind Direction은 'Unknown' / Condition은 'Fair' / 나머지 모든 열은 0으로 해서
나머지 4개의 Clean Missing Data 컴포넌트를 추가해서 쭉 연결시킴
< 데이터 변환 >
만약 날씨 상태(Condition)에서 맑음, 흐림, 번개를 1,2,3 이렇게 구분해버리면, 머신은 번개 = 3을 더 가중치가 높은 값으로 인식해버린다.
그러므로 이런 문자열 데이터 형식을 범주형 데이터로 변경 후, 범주형 데이터를 다시 Indicator value로 변환해야 한다.
(머신러닝은 데이터를 숫자 형태의 indicator로 변환하여 처리)
예를들어 Crewed / Uncrewed를 Indicator value로 변환하면 1열이, 2열로 늘어나 0과1로 수치화해서 표현한다.
( 그냥 string 일때는 0과1로 표현 못하니까 범주형으로 바꾸는 과정이 필요함 )
( 고유값 여러 개이면 수치의 높낮이가 있는게 아니라서 그냥 숫자로 표현하면 훈련이 안됌 그래서 있냐/없냐로 하기 위해 indicator value로 바꾼거임 )
( 날씨 상태로 치면 6열로 늘어나서 맑음- 있냐/ 맑음 - 없냐 / 흐림- 있냐 / 흐림 - 없냐 / 번개- 있냐 / 번개 - 없냐 )
우선 문자열 데이터 형식을 범주형 데이터로 변경할것이다.

“Edit metadata” 컴포넌트 추가후 연결 – 열편집

열이름에 Crewed or Uncrewed / Wind Direction / Condition 입력후 저장
Data type = String, Categorical = Categorical, Fields = Features 으로 변경후 저장
( 데이터 타입을 String에서 Categorical로 변경하는 것 )
( Fields는 학습 알고리즘이 이 데이터를 label로 취급할지, feature로 취급할지 정하는 것 )
[입력(input) + 타켓(target)]
지도 학습에서 주어진 데이터를 데이터의 특징을 나타내는 입력(input, feature),
예측하고자 하는 정답을 나타내는 타켓(target, label)으로 구분
이제 범주형 데이터에서 지시값 형식으로 변경할것이다.
( 변환하면 각 열의 고유값 개수만큼 열이 늘어남 )
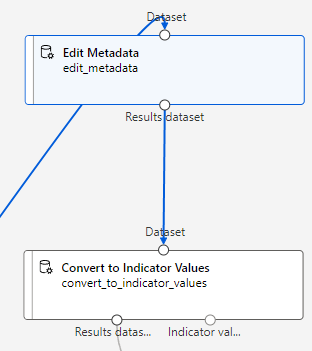
“Convert to Indicators Values” 컴포넌트 추가후 연결 – 열편집
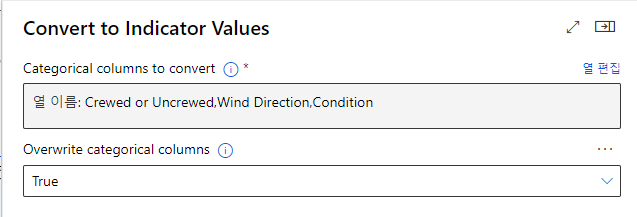
열이름에 Crewed or Uncrewed / Wind Direction / Condition 입력후 저장
Overwrite categorical columns을 True로 변경
( 범주형 데이터 타입을 지시값을 나타내는 숫자 형태의 타입으로 변환 )
6. 데이터 분리
전체 데이터 세트를 모델 훈련에 사용할 '학습 데이터'와 예측 정확도 확인을 위한 '테스트 데이터'로 나눠야함
학습에 사용되었던 데이터를 테스트 데이터에 사용할 경우, 그 데이터에만 잘 맞는 과대적합(overfitting)문제가 발생하기 때문에 모델 성능을 제대로 평가하기 위해 나눠줘야함

“Split Data” 컴포넌트를 추가후 연결

Fraction of rows 를 0.7로 변경( 학습: 70%/ 테스트: 30% )
Randomized split : 행 기준으로 무작위로 분리
Random seed : 난수 초깃값
( 무작위 추출을 통해 샘플링 편향이 최소화 되도록 함 )
7. 모델링 알고리즘 선택
“Two-Class Decision Forest ”(랜덤 포레스트) 컴포넌트 추가후 설정
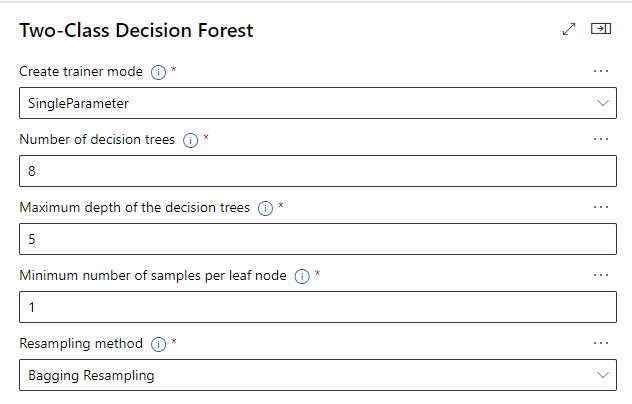
의사결정트리 적용할 개수 = 8
최대 깊이 = 5 ( 너무 높은 값은 과적합 발생 )
리프노드의 최소 샘플수 = 1
샘플링 방법 = Bagging(중복허용)
7. 모델 학습(훈련)
이제 훈련 모델에 선택한 알고리즘과 훈련 데이터를 연결해줘야한다.
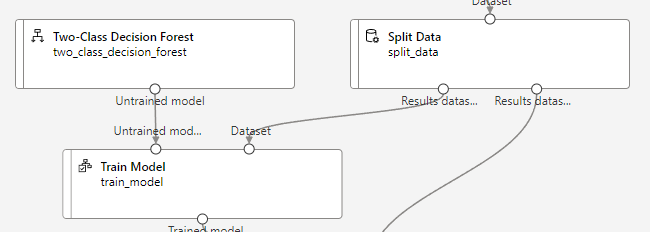
“Train Model” 컴포넌트 추가후 알고리즘과 훈련 데이터를 연결
(Split Data에서 왼쪽 : 훈련 데이터 / 오른쪽 : 테스트 데이터)

Label column에는 열이름 = “Launched?” 추가후 저장
Model explanations : True
( Label에는 예측하고자 하는 정답 컬럼을 넣어야함, 로켓 발사를 했냐, 안했냐니까 Launched? )
8. 모델 테스트
이제 학습된 모델의 테스트 결과를 산출하기 위해 훈련된 모델과 테스트 데이터를 연결해줄것이다.
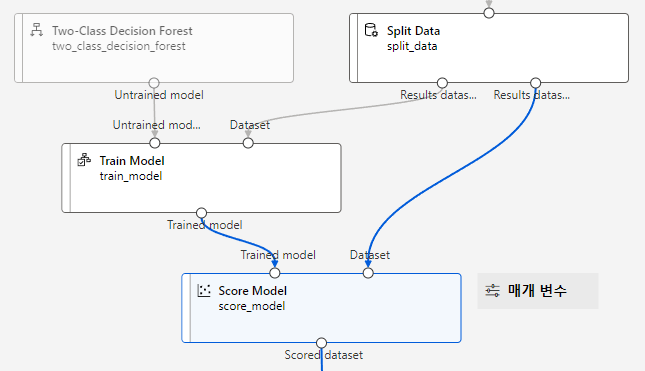
“Score Model” 컴포넌트 추가후 훈련된 모델과 테스트 데이터를 연결
테스트 데이터를 학습된 모델에 적용해 날씨 조건에 따른 로켓 발사 가능 여부 및 확률을 예측함
9. 모델 평가
실제 데이터세트의 정답 값과 테스트를 수행하여 예측한 값을 비교해서
모델의 정확도, 성능을 여러 지표로 평가하기 위해 Evaluate Model를 사용할 것이다.
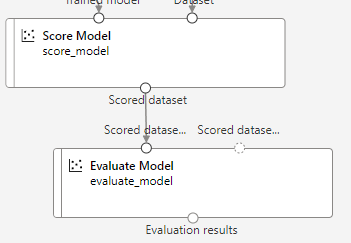
“Evaluate Model” 컴포넌트를 추가하고 Scored dataset을 연결후 저장
10. 결과 확인
과정 중 파이프라인을 연결 후 중간마다 결과를 확인하고 싶으면
"저장"을 누르고 "구성 및 전송"을 클릭
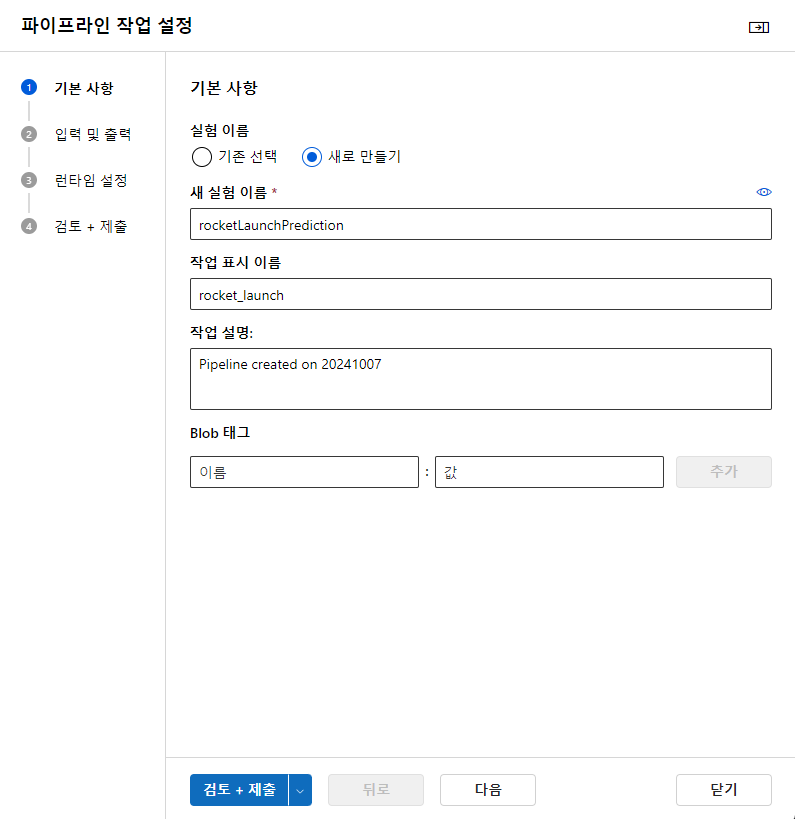
실험을 "새로 만들기"로 하고 이름 : rocketLaunchPrediction
런타임 설정에서 컴퓨팅 유형 : 컴퓨팅 인스턴스, 우리가 만들었던 컴퓨팅 선택 (b015-ml-vm)
데이터 저장소 : workspaceblobstore
검토후 제출
자산 - 파이프라인에 들어가면 실행 중인 실험들을 확인 가능
실험에 들어가서 오른쪽 클릭후 데이터 미리보기로 작업된 결과물 확인 가능
< Score Model 결과 확인 >

Scored Labels에는 로켓 발사 가능 여부, Scored Probabillities에는 예측 확률을 확인할 수 있다.
true는 발사 가능하다는 것이고, false는 발사 불가능하다는 것이다.
시각화에서 보면 발사 가능한 날보다 불가능한 날이 훨씬 많아보인다.
< Evaluate Model 결과 확인 >

모델이 얼마나 정확하게 평가했는지에 대한 지표이다.
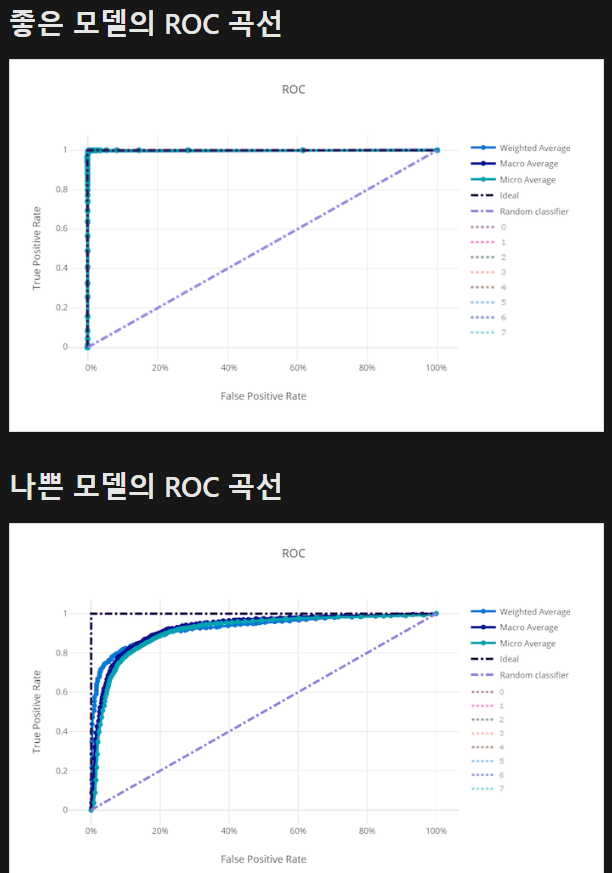

- ROC 곡선 : 민감도(Sensitivity) (또는 재현율(Recall))와 1 - 특이도(Specificity) 사이의 관계를 시각화한 곡선
=> 모든 임계값(가양성 비율)에서의 분류 모델의 성능을 확인할수 있음
=> AUC(곡선 아래면적) 값이 1에 가까울수록 성능이 좋으며, 0.5는 무작위로 분류하는 것과 동일한 성능을 의미
- 정밀도-회수 곡선 : 정밀도(Precision)와 재현율(Recall) 간의 관계를 시각화한 곡선
=> 데이터세트의 불균형이 심할 때 사용
=> 양성 클래스(우리가 식별하고자 하는 클래스)의 성능을 평가 가능
=> 1을 유지하는 부분은 양성으로 예측한 데이터 중 대부분이 실제로도 양성임을 나타내고, 급격하게 떨어지는 부분은 특정 임계값 이후 예측 성능이 급격하게 떨어지는 것을 의미함
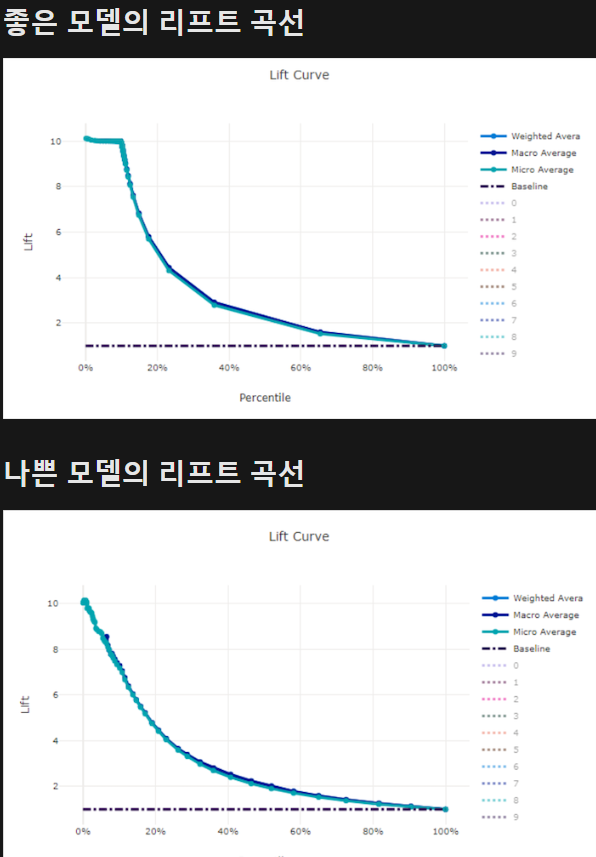
- 리프트 곡선 : 실제로 타겟 클래스를 얼마나 더 잘 예측하는지를 나타내는 곡선
=> 모델이 무작위 예측보다 얼마나 더 좋은 성능을 내는지를 평가.
=> 처음에 급격하게 올라가는 부분은 상위 비율의 샘플에서 매우 강력한 성능을 발휘하고 있음을 나타내고, 이후 안정화되는 부분은 전체 데이터셋에 가까워질수록 무작위와 비슷한 성능을 보인다는 것이다.
( 상위 비율 : 모델이 가장 높은 확률로 양성이라고 예측한 샘플들 중 상위 몇 퍼센트에 해당하는지 나타냄 )
=> 처음에는 급상승을 하다가 나중에 점점 감소하는 형태가 좋은 모델, 예측 확률이 높은 자신있는 것들은 높은 정확성을 가지는것이고, 점차 확률이 낮은 샘플들까지 예측할수록 예측의 정확성이 줄어드는게 자연스럽기 때문이다.
오히려 나중에 낮아지지 않고 안정화되며 유지가 되는것은 "과도한 자신감"을 가진것이라서 문제가 발생할 수 있다.

- 오차 행렬(Confusion Matrix) : 이진 분류의 예측 오류가 얼마인지, 어떠한 유형의 예측 오류가 있는지 확인 가능한 지표
=> TP : 맞다고 예측했는데 실제로 맞음 , FP : 맞다고 예측했는데 실제는 아님 , FN , TN
=> 정확도 : 모든 결과 중 모델이 맞춘 비율, (TP + TN) / (전체)
=> 정밀도 : 모델이 맞다고 예측한것중 실제로 맞는 비율, TP / (TP+FP)
=> 재현율(회수) : 실제로 맞는것중 모델이 맞춘 비율, TP / (TP+FN)
- 임계값 : 특정 확률 이상의 예측값을 Positive로 예측함
=> 적절한 임계값 조절하여 정확도를 확인해야함
=> 될꺼라고 봐주는 정도?, 10%확률로 우리나라가 이길거야 -> 10%조차 믿겠다 -> 임계값을 낮추면 이렇게 됌,
임계값이 낮아지면 낮은 확률도 될거라고 생각해버리는 것(암진단)
=> 반대로 오히려 임계값이 너무 높으면 실제 로켓을 발사할 확률이 높아도 발사 안될꺼라고 판단(버섯도 잘못판단하면 X)
- 진양성 수 : 제대로 예측한것( 맞다고 예측했는데 실제로 맞는 것)
- 가양성 수 : 잘못 예측한것
결론적으로, 1에 가까운 ROC 곡선의 아래 면적과 많은 진양성 수를 보아 이 모델은 잘 훈련되었다고 볼 수 있다.
'클라우드' 카테고리의 다른 글
| Azure Machine Learning을 통한 야구 선수 능력 측정 모델 구현(군집) (3) | 2024.10.14 |
|---|---|
| Azure Machine Learning을 통한 자전거 렌탈 수요 예측 모델 구현(회귀) (1) | 2024.10.13 |
| Azure Machine Learning을 이용해 Stable Diffusion 사용하기 (1) | 2024.09.29 |
| Microsoft Azure VM에 블로그 만들기 (10) | 2024.09.29 |