
Microsoft AI School에서 지원 받은 계정을 이용해 자전거 렌탈 수요 예측 모델을 구현해볼 것이다.
MS Azure의 Machine Learning Studio에서 Designer를 활용해 파이프라인을 구성하여 모델을 훈련시키고 평가할것이다.
기본적인 디자이너 관련 내용은
Azure Machine Learning을 통한 로켓 발사 여부 예측 모델 구현
Microsoft AI School에서 지원 받은 계정을 이용해 로켓의 발사일 예측 모델을 구현해볼 것이다.MS Azure의 Machine Learning Studio에서 Designer를 활용해 파이프라인을 구성하여 모델을 훈련시키고 평가할것
samdo3.tistory.com
여기에 나와있다.( 지도학습 - 분류 : 범주 예측(True/False ) )
그러므로 이 글에서는 알고리즘 관련으로 집중해서 다룰것이다.
- 데이터 세트 :
UCI에서 제공하는 2011년부터 2012년까지 Capital bikeshare system에서 대여된 자전거의 시간당 및 일당 수와 해당 날씨 및 계절 정보이다. ( https://archive.ics.uci.edu/dataset/275/bike+sharing+dataset )

일 / 월 / 년 / 계절 / 공휴일 / 요일 / 근무일 / 날씨 / 온도 / 체감온도 / 습도 / 바람세기 / 자전거 렌탈수
( 날씨 :
- 1: Clear, Few clouds, Partly cloudy, Partly cloudy
- 2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
- 3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
- 4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
)
- 알고리즘 :
날씨,계절, 휴뮤일 여부에 따라 렌탈 수요값이 달라지므로 지도 학습의 Regression을 사용
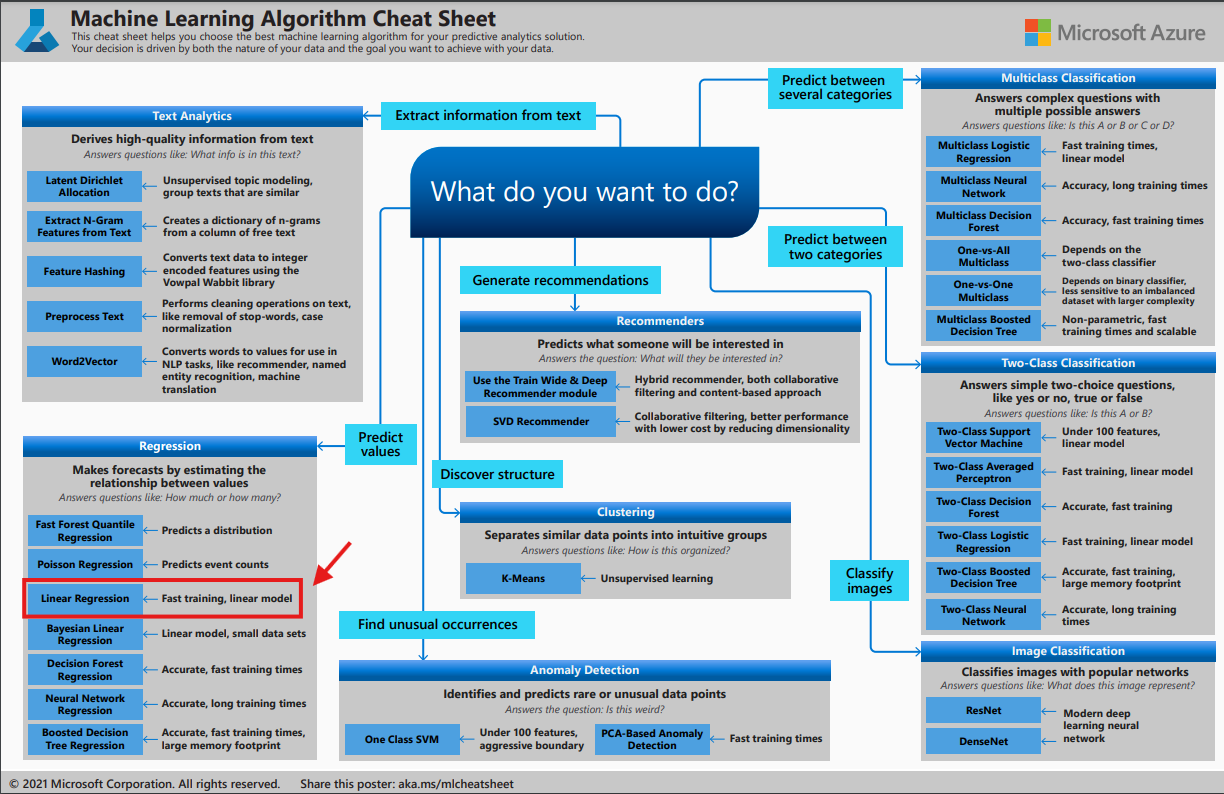
선형 회귀 : 독립변수와 종속변수의 관계를 선형 관계로 모델링, 임의의 연속적인 수치를 예측
=> y= wx + b ( x : 독립변수 / y : 종속변수 / w : 가중치 / b : 편향 )
=> 오차를 최소화할 수 있는 기울기와 절편(회귀선)을 찾기 위해 MSE, MAE를 사용( 오차 = 실측값과 예측값의 거리 )
비용 함수 :
MAE = 오차의 절대값을 평균, 0에 가까울수록 오차없음, L1 Loss
MSE = 오차의 제곱을 평균, 정사각형 면적이 작을수록 오차없음, L2 Loss
경사하강법 : 비용함수를 사용하여 오차를 줄이는 방향으로 학습
=> 오차가 최소가 되는 방향으로 가중치를 조정(update)해가며 학습
학습률(learning rate) : 경사하강법은 기울기에 학습률이라는 스칼라 값을 곱해서 다음지점을 정함
수렴 : 선형회귀분석은 비용함수 및 경사하강법 등을 이용해 회귀계수의 최적값을 찾아나감
=> 반복하여 학습하면 특정 값으로 수렴함
과소적합 : 학습데이터 충분하지 않아 최적화가 제대로 수행되지 않아 구조와 패턴 반영 못함
과대적합 : 학습데이터 지나치게 학습해 테스트 데이터에서 성능이 떨어짐
=> 적합한 값으로 학습해야함
다중 선형 회귀 : 하나의 결과를 여러 원인으로 설명 가능, y= w1x1 + w2x2 + ... + wnxn + b
=> 다중회귀모델의 L1 규제(라쏘) / L2 규제(릿지)를 통해 가중치의 영향력을 제한해 과대 적합을 방지함
(W1,W2,..,Wn의 크기(양)에 패널티를 부여)
규제의 양 = 람다값, 적절한 람다값으로 데이터를 잘 반영한 회귀계수를 찾게 된다
=> 람다값이 큰 경우(강한 규제) => 과소적합 유발
=> 람다값이 작은 경우(약한 규제) => 과대적합 유발
실습에는 여러 요인으로 자전거 렌탈 수요가 결정되므로 "다중 선형 회귀" 사용해야함
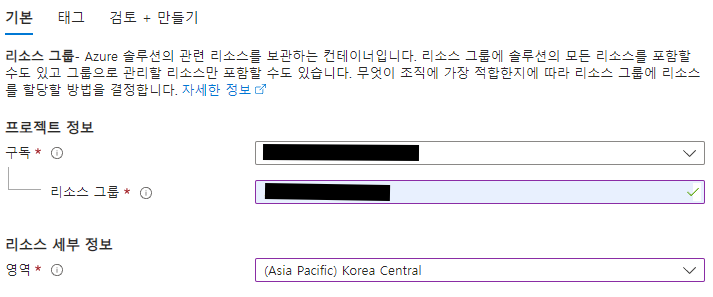
1. 리소스 그룹 만들기

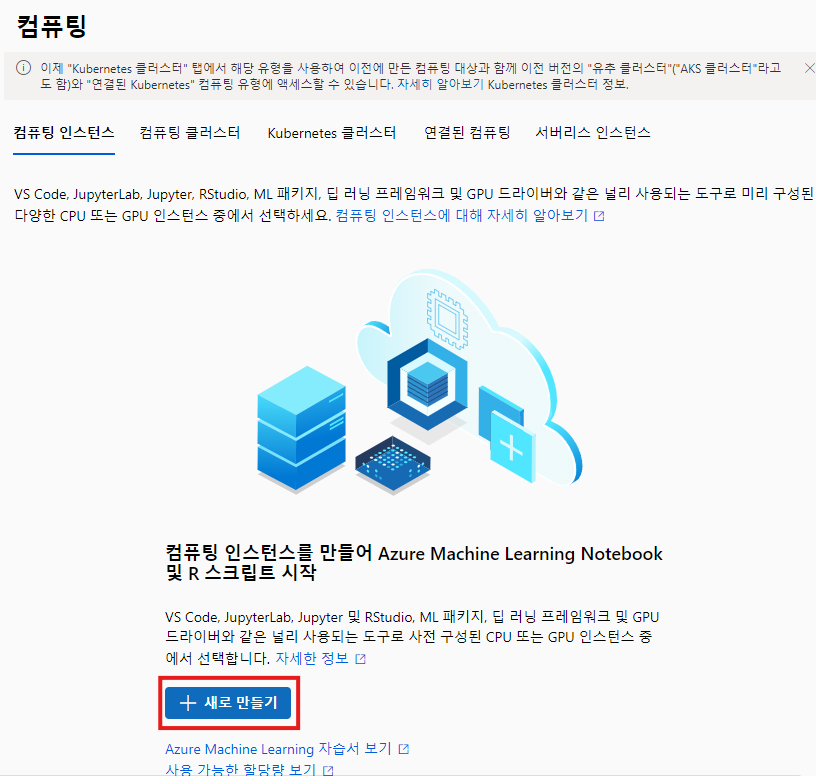
2. Machine Learning Studio에서 컴퓨팅 생성
3. 데이터세트 등록
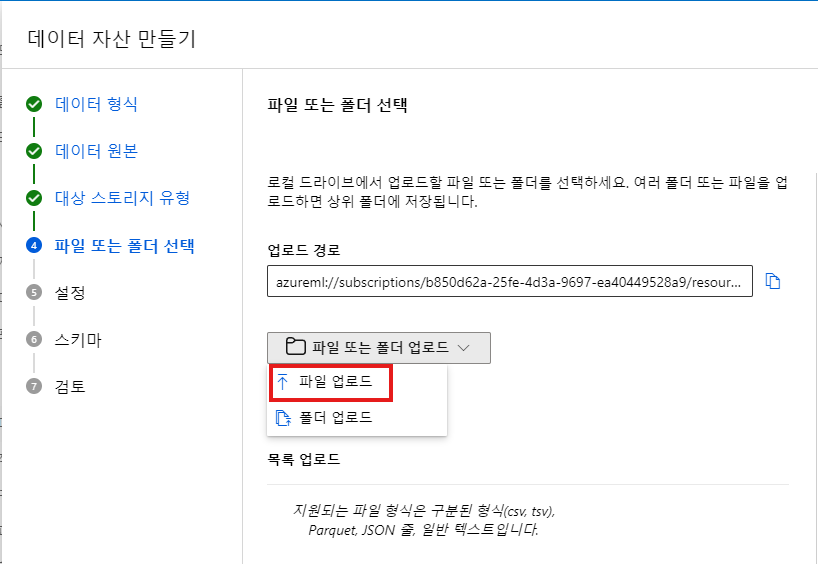
스튜디오에 자전거 렌탈 데이터세트(daily-bike-share.csv) 올림
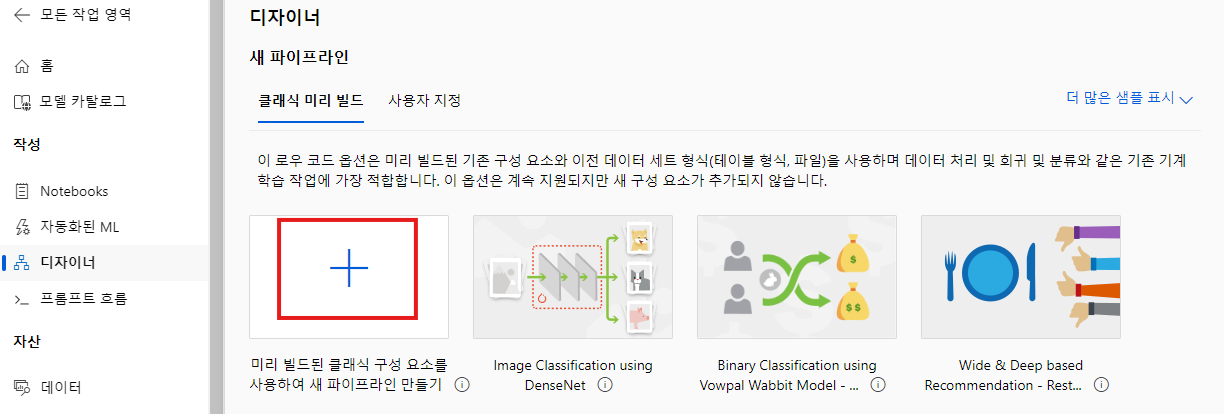
4. 머신러닝 디자이너 시작
5. 데이터세트 전처리

< 불필요한 컬럼 제외 >
학습에 유의미한 데이터만 남기기 위해 필요 없는 컬럼들을 없애줄거임
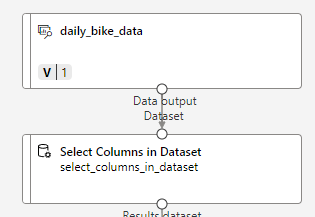
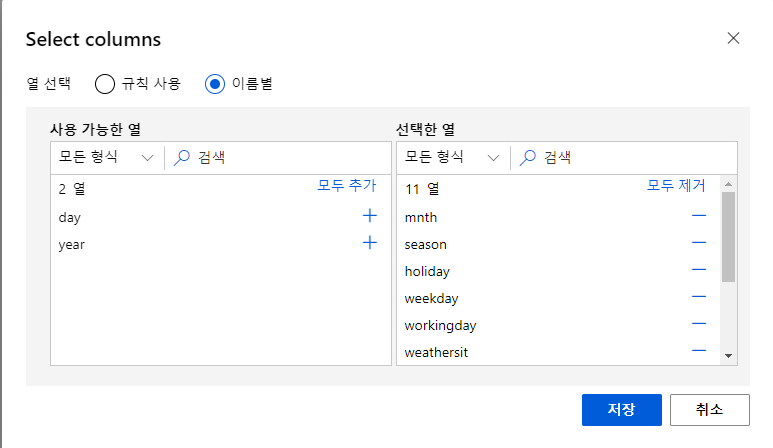
day, year 빼고 전부 다 특성으로 선택
< 누락값 처리 >

데이터에 누락값 없음
< 데이터 변환 >
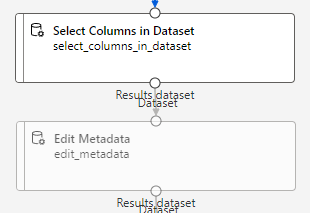
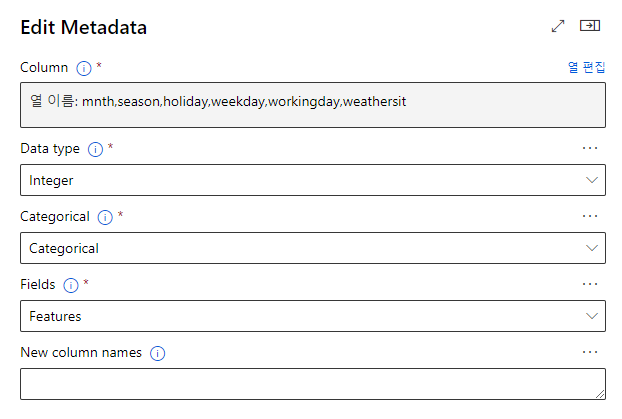
mnth, season, holiday, weekday, workingday, weathersit => 범주형 데이터로 변환
- 데이터 타입 : integer ( 정수값 -> 범주형 데이터 )
- 카테고리 : Categorical
- 필드 : Features ( input 값들 )


범주형 데이터 => 지시형 값으로 변환
- Overwrite categorical columns : True ( 선택된 컬럼에 덮어쓰면서 열 늘어남 )
< 정규화 및 표준화 >
온도, 체감온도, 풍속, 습도등은 서로 단위,분포가 다르므로 정규화, 표준화가 필요
정규화 : 범위, 단위가 다른 값들을 [0,1] 사이의 값들을 갖도록 변환
표준화 : 평균이 0, 표준편차가 1이 되도록 값들을 변환
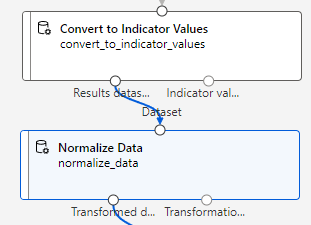

temp, atemp, hum, windspeed => 정규화
- 변환 방법 : ZScore ( 모든 값을 z-점수로 변환해 정규화 시키는 함수 )

- Use 0 for constant columns when checked : 숫자 열에 단일 불변 값이 포함되어 있는 경우 이러한 열이 정규화 작업에 사용되지 않음
6. 데이터 분리


70%(훈련) / 30%(테스트) 로 데이터 분리
7. 모델링 알고리즘 선택
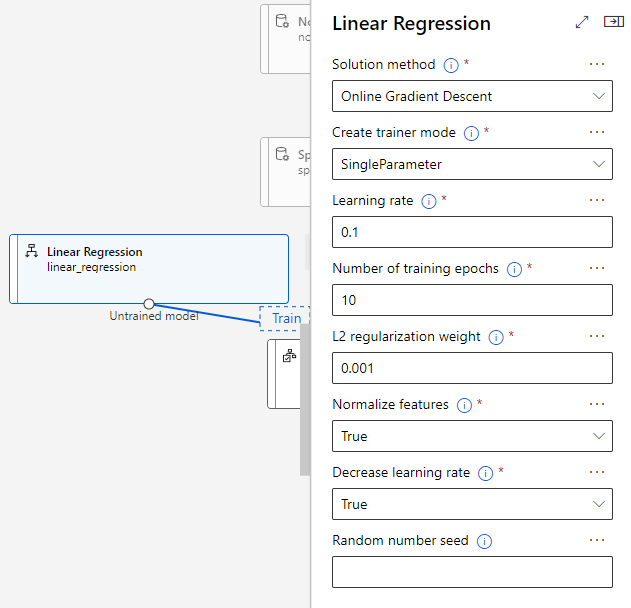
"Linear Regression" 컴포넌트 사용
- Solution method : Online Gradient Descent(경사하강법)
- Create trainer mode : SingleParameter( 하이퍼파라미터 하나씩 설정하여 학습 )
- Learning rate : 0.1 ( 경사하강법의 학습률, 보통 0.01이 가장 좋은값 )
- Number of training epochs : 10 ( 전체 학습 데이터를 학습시키는 횟수 )
- L2 regularization weight : 0.001 ( L2 규제의 양(람다), 규제 중 릿지 규제 사용 )
- Normalize features : False ( 선형 회귀에 사용할 특성들을 정규화, 비교했을때 False가 더 잘 훈련됌 )
- Decrease learning rate : True ( 반복이 진행됨에 따라 학습률이 감소해야 하는지 여부 표시 )
8. 모델 학습(훈련)

“Train Model” 컴포넌트 추가후 선형회귀, 훈련 데이터 연결
Label 열에 “rentals” 추가후 저장 ( target 값 )
9. 모델 테스트

“Score Model” 컴포넌트 추가후 훈련된 모델, 테스트 데이터 연결
학습한 모델이 테스트 데이터에 대한 자전거 렌탈수를 예측
10. 모델 평가
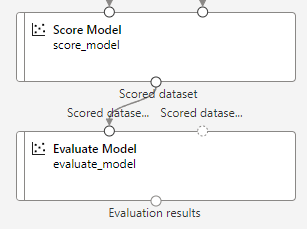
“evaluate model” 컴포넌트까지 추가후 연결
저장후 결과 확인
< Score Model 결과 확인 >

Scored Labels는 모델이 예측한 자전거 렌탈수인데, 음수 값은 예측을 잘못한것으로 보면 된다.
< Evaluate Model 결과 확인 >
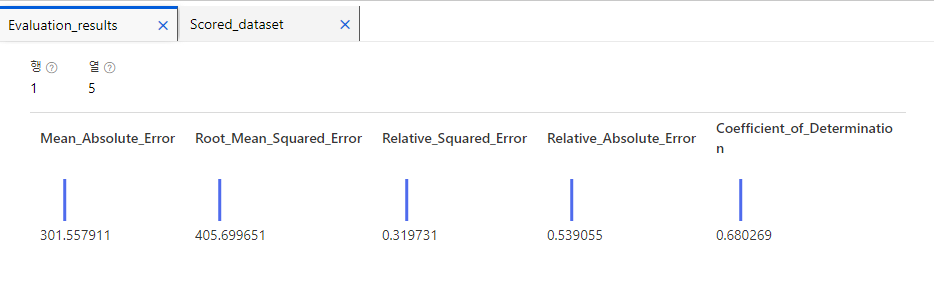
평가 지표 = 오차(손실) 확인
1. MAE : 오차의 절대값을 평균한 값, 독립변수의 단위 유지, 0에 가까울수록 오차없음
2. RMSE : 오차의 제곱을 평균한 값의 제곱근, 이상치에 민감함, 0에 가까울수록 오차없음
(MSE의 제곱근, RMSE가 머신러닝 모델의 정확도를 예측하는 평가자료로 널리 사용됌 )
3. RSE : MSE를 실제값과 평균값의 차이의 제곱평균으로 나눈 값, 0에 가까울수록 오차없음
( 예측값의 평균과 단위에 민감하지 않아 다른 단위로 오류가 측정되는 모델과의 비교에 사용됨, 이상치에 민감함)
4. RAE : MAE를 실제값과 평균값의 절대차의 평균으로 나눈 값, 0에 가까울수록 오차없음
( 예측값의 평균과 단위에 민감하지 않아 다른 단위로 오류가 측정되는 모델과의 비교에 사용됨, 이상치에 민감하지 않음)
5. R^2 결정계수( Coefficient_of_Determination ) :
모델의 독립변수들이 종속변수를 얼마나 잘 설명하는지 나타내는 지표( 설명력 )
( 1에 가까울수록 더 잘 설명함 )
RSE, RAE, R^2 결정계수를 보아 어느정도는 잘 설명해주는 모델인 것 같다.
'클라우드' 카테고리의 다른 글
| Azure Machine Learning을 통한 야구 선수 능력 측정 모델 구현(군집) (3) | 2024.10.14 |
|---|---|
| Azure Machine Learning을 통한 로켓 발사 여부 예측 모델 구현(분류) (0) | 2024.10.13 |
| Azure Machine Learning을 이용해 Stable Diffusion 사용하기 (1) | 2024.09.29 |
| Microsoft Azure VM에 블로그 만들기 (10) | 2024.09.29 |